Test your AI interfaces. AI analyzes your results.¶
A pytest plugin for validating whether language models can understand and operate your MCP servers, tools, prompts, skills, and custom agents. AI analyzes your test results and tells you what to fix, not just what failed.
The Problem¶
Your MCP server passes all unit tests. Then an LLM tries to use it and:
- Picks the wrong tool
- Passes garbage parameters
- Can't recover from errors
- Ignores the skill instructions you bundled with it
Why? Because you tested the code, not the AI interface.
For LLMs, your API isn't functions and types — it's tool descriptions, skills, custom agent instructions, and schemas. These are what the LLM actually sees. Traditional tests can't validate them.
The Solution¶
Write tests as natural language prompts. A CopilotEval is your test harness — it combines the configuration you want to evaluate:
from pytest_skill_engineering.copilot import CopilotEval
async def test_balance_and_transfer(copilot_eval):
agent = CopilotEval(
name="banking-test",
skill_directories=["skills/financial"], # Eval Skill (optional)
)
result = await copilot_eval(
agent,
"Transfer $200 from checking to savings and show me the new balances.",
)
assert result.success
assert result.tool_was_called("transfer")
The LLM runs your prompt, calls tools, and returns results. You assert on what happened. If the test fails, your tool descriptions or skill need work — not your code.
This is skill engineering: design a test for what a user would say, watch the LLM fail, refine your tool descriptions until it passes, then let AI analysis tell you what else to optimize. See Skill Engineering for the full concept.
What you're testing:
| Component | Question It Answers |
|---|---|
| MCP Server Tools | Can an LLM understand and use my tools? |
| MCP Server Prompts | Do my bundled prompt templates render correctly and produce the right LLM behavior? |
| Prompt Files (Slash Commands) | Does invoking /my-command produce the right agent behavior? |
| Skill | Does this domain knowledge help the LLM perform? |
| Custom Agent | Do my .agent.md instructions produce the right behavior and subagent dispatch? |
What Makes This Different?¶
AI analyzes your test results and tells you what to fix, not just what failed. It generates interactive HTML reports with eval leaderboards, comparison tables, and sequence diagrams.
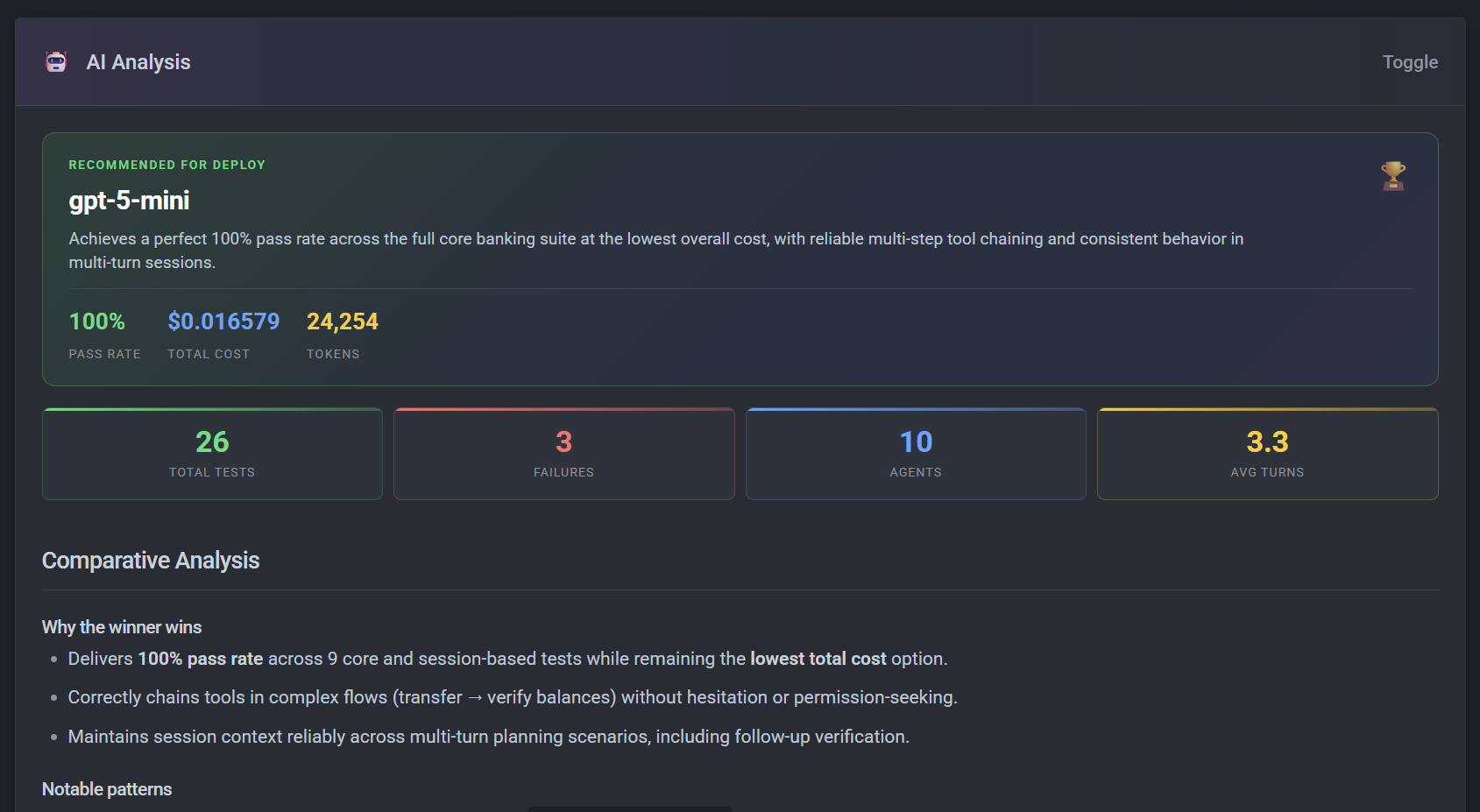
See a full sample report →{ .md-button }
**Suggested improvement for `get_all_balances`:**
> Return balances for all accounts belonging to the current user in a single call. Use instead of calling `get_balance` separately for each account.
**💡 Optimizations**
**Cost reduction opportunity:** Strengthen `get_all_balances` description to encourage single-call logic instead of multiple `get_balance` calls. **Estimated impact: ~15–25% cost reduction** on multi-account queries.
Quick Start¶
GitHub Copilot (recommended)¶
Test what your users actually experience — zero model setup:
from pytest_skill_engineering.copilot import CopilotEval
async def test_skill(copilot_eval):
agent = CopilotEval(skill_directories=["skills/my-skill"])
result = await copilot_eval(agent, "What can you help me with?")
assert result.success
📁 See copilot/test_01_basic.py for complete examples.
Specify a model¶
Full control over model selection and cost tracking:
from pytest_skill_engineering.copilot import CopilotEval
async def test_balance_check(copilot_eval):
agent = CopilotEval(
name="banking-test",
model="gpt-5.4-mini",
)
result = await copilot_eval(agent, "What's my checking account balance?")
assert result.success
assert result.tool_was_called("get_balance")
📁 See copilot/test_01_basic.py for complete examples.
Features¶
- MCP Server Testing — Real models against real tool interfaces; verify LLMs can discover and use your tools
- MCP Server Prompts — Test bundled prompt templates exposed via
prompts/list; verify they render correctly and produce the right LLM behavior - Prompt File Testing — Test VS Code
.prompt.mdand Claude Code command files (slash commands) withload_prompt_file()/load_prompt_files() - A/B Test Servers — Compare MCP server versions or implementations
- Test CLI Tools — Wrap command-line interfaces as testable servers
- Compare Models — Benchmark different LLMs against your tools
- Eval Skills — Add domain knowledge following agentskills.io
- Custom Agents — Test
.agent.mdcustom agent files withCopilotEval; A/B test custom agent versions - Real Coding Agent Testing — Test real coding agents like GitHub Copilot via the SDK (native OAuth, skill loading, exact user experience)
- Eval Leaderboard — Auto-ranked by pass rate and cost; AI analysis tells you what to fix
- Multi-Turn Sessions — Test conversations that build on context
- Copilot Model Provider — Use
copilot/gpt-5.4-minifor all LLM calls — zero Azure/OpenAI setup - Clarification Detection — Catch evals that ask questions instead of acting
- Semantic Assertions —
llm_assertfor binary pass/fail checks on response content - Multi-Dimension Scoring —
llm_scorefor granular quality measurement across named dimensions - Image Assertions — AI-graded visual evaluation of screenshots and visual tool output
- Cost Estimation — Automatic per-test cost tracking with pricing from
pricing.toml
Installation¶
Who This Is For¶
- MCP server authors — Validate tool descriptions work
- Eval builders — Compare models and prompts
- Copilot skill and custom agent authors — Test exactly what your users experience, before you ship
- Teams shipping AI systems — Catch LLM-facing regressions
Why pytest?¶
This is a pytest plugin, not a standalone tool. Use existing fixtures, markers, parametrize. Works with CI/CD pipelines. No new syntax to learn.
Documentation¶
- Getting Started — Write your first test
- How-To Guides — Solve specific problems
- Reference — API and configuration details
- Explanation — Understand the design
License¶
MIT